MySQL索引与B+树
索引是 MySQL 中最重要的功能之一。
在日常使用数据库的过程中,使用的最多功能是:
- 根据某一列特定的值查找数据
- 根据某一列特定值的范围查找数据。
在数据库中数据规模不大的情况下,每次查询都进行全表的扫描查询,这样也是可以接受的。一旦数据库的数据规模增长了很大之后,如果还是使用全表扫描的方式,那么查询的性能就会直线下降。
索引的存在就是为了解决这个问题的。理解索引最好的方式就是类比树的目录。实际上这两者的思想也是类似的。对于书的目录,有两个很重要的特性:
- 目录是按照内容的顺序组织起来的
- 目录中不包含所有的内容,只包含章节的标题
这两点也是索引最重要的特性。第一个特性保证了可以支持区间查找和排序,第二个特性保证了索引的查询要比直接全表扫描的速度快的多。
那么索引的底层数据结构是什么呢?如果才能满足索引的这些要求。MySQL 中目前使用的最为广泛的索引的底层数据结构就是 B+ 树。
B+ 树
B+ 树是基于 B 树改造而来的,B 树就是平衡树(Balance Tree),二叉查找树就是一种典型的平衡树。
B+ 树与二叉查找树的结构很像,但是 B+ 树与二叉查找树最大的不同之处有两个地方:
- B+ 树的所有节点通过一条双向链表连接
- B+ 树不是二叉,是 m 叉,m 的值根据实际的情况调整
所以 B+ 树是下面这个样子:
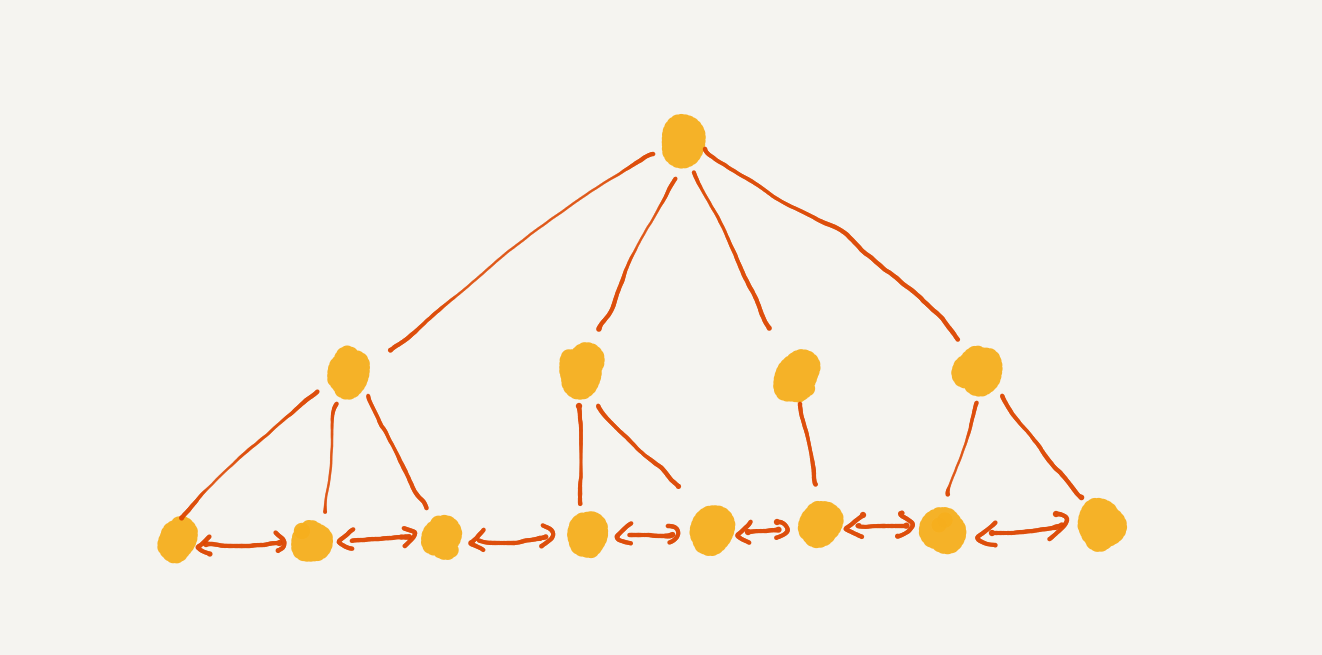
对于 B+ 树来说,这两个设计很关键,第一个是为什么要使用双向链表,因为索引需要支持区间查找,如果使用单链表,那就只能支持单向区间查找了,反向的查找就支持不了,比如 :
select * from students where age < 18;
第二就是为什么 B+ 树是 m 叉,而不是二叉。二叉树的每个节点最多有两个子节点,如果一张数据库表中的数据有百万条,那么按照二叉树的方式来构造索引,二叉树的高度就会过高。这样会带来两个问题:
- 树的高度过高就会占据更多的内存,这个与建立索引的初衷相违背
- 索引是不断在动态调整的,如果树的高度过高,在调整的过程中就会带来更多的元素移动和计算
为了避免上述的原因,B+ 被设计成了 m 叉树。B+ 树与跳表的结构非常类似。
即使是设计成了 m 叉树,也还是存在没有解决的问题。因为索引是在数据的增删改查中不断被动态调整的。所以很有可能出现某个节点的节点树超过了 m 个,如果不对这种情况进行处理,最后 B+ 树甚至会退化成一个链表。还有就是一个节点上的数据不断被删除,最后剩下的节点远远少于 m 个,这样就会造成空间的浪费。
针对这些情况,都需要在索引更新的过程中进行调整。如果一个节点的子节点超过了 m,那就会将这个节点分裂成两个节点,如果一个节点的节点数少于 m / 2,那么就会将这个节点与相邻的节点进行合并。通过这样的方式来保证 B+ 树上所有的节点是均衡分布的。
MySQL 索引
MySQL 中索引是在存储引擎上实现的。除了 B+ 树索引外,也还支持其他的索引,但是 B+ 树是使用的最为广泛的索引。
- B+ 树索引:大多数 MySQL 存储引擎默认的索引
- 哈希索引:$O(1)$ 的查找效率,但是失去了有序性,不支持范围查找
- 全文索引:MyISAM 存储引擎支持的全文索引
- 空间数据索引:用于存储地理数据
使用索引减少了数据查询时需要扫描的数据行数。之前有提到索引都是按照内容的顺序组织起来的。所以通过索引查询时也就避免了创建临时表去排序,特别是在查询语句种使用了 order by 和 group by 时。
但是也不是所有的情况都适合使用索引,在数据库中数据规模很小时,使用索引还不如不使用的效率高。对于特大型的表,维护索引的代价太大,这个时候索引已经解决不了问题了,可能就需要考虑使用拆分数据库了。
索引的优化
索引必须使用在独立的列上
索引必须单独使用,不能是表达式,也不能是函数的参数:
select * from students where age + 1 > 19;
上面的用法就会导致 age 上的索引失效
多列索引
索引可以多列组合使用:
select * from students where name = 'xm' and age = 18;
索引的排列顺序
在使用索引时,需要注意索引列的排列顺序,应当将索引选择性大的列放在前面。比如上面 sql 中的 name 和 age 列,假设 name = 'xm' 可以区分出查找出 5 条记录,而 age = 18 可以查出 20 条记录,那么 name 索引的选择性就是大于 age 的。
前缀索引
对于 BLOB 、TEXT 、VARCHAR 类型的列,必须使用前缀索引,只索引前面特定长度的字符。
如果对整个字段进行索引,就会导致整个索引过于庞大,反而会降低查询的效率。
覆盖索引
索引中包含所有需要查询的值。
(完)