Java容器系列-Java容器总览
Java 的容器是 Java 语言中很重要的一部分,日常写代码会大量用到各种容器。Java 中的容器有一个庞大的体系,纠缠于细节很难全面掌握。这篇文章就总览一下 Java 的容器,然后再深入到细节中学习。
Java 中的容器主要分为两部分,Collection 和 Map 两种。Collection 主要用于存储单个的元素。而 Map 则主要是存储键值对。
本文基于 JDK1.8
Collection
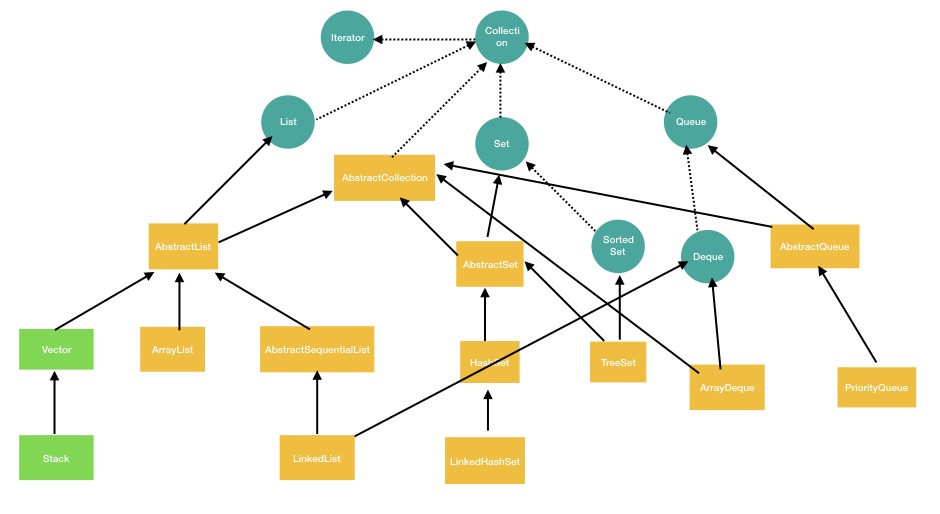
上图中圆圈代表接口, 长方形代表类,包括抽象类和普通类。绿色代表线程安全,黄色代表不是线程安全。上面的类图中只包括了 java.util 下的类,java.util.concurrent 下面的容器类从功能的角度上来说并没有太大不同,但是这个包下的类都是线程安全的。
从类图中可以看到 Collection 继承了 Iterator 接口,说明所有的 Collection 都可以通过迭代器来进行访问。
Collection 接口有三个子接口,List、Set 和 Queue。List 会按照元素的插入顺序保存元素,Set 中的元素都不能重复。Collection 中定义了一些公共的方法,都是一些基础的工具方法,比如获取容器的大小、判断容器时候为空、清空容器、迭代容器元素等方法。在 JDK1.8 以后,在 Collection 接口中加入了 default 方法,这些方法都是用于支持 Java8 的函数式编程。
interface Collection<E> extends Iterable<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
default <T> T[] toArray(IntFunction<T[]> generator) {
return toArray(generator.apply(0));
}
boolean add(E e);
boolean remove(Object o);
boolean containsAll(java.util.Collection<?> c);
boolean addAll(java.util.Collection<? extends E> c);
boolean removeAll(java.util.Collection<?> c);
default boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
boolean removed = false;
final Iterator<E> each = iterator();
while (each.hasNext()) {
if (filter.test(each.next())) {
each.remove();
removed = true;
}
}
return removed;
}
boolean retainAll(java.util.Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
}
List
List 接口下的 ArrayList 日常写代码使用的很多。ArrayList 的部分代码如下。从代码中可以看到,ArrayList 底层的数据结构就是一个数组,而且 ArrayList 实现了 RandomAccess 来支持随机访问。
class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
transient Object[] elementData;
}
ArrayList 与数组的功能很像,但是提供了更多便利的操作。Vector 与 ArrayList 的功能基本一致,但是是线程安全的,Vector 的子类 Stack 同样也是线程安全的,但是这些类基本都不推荐再使用了。如果要使用线程安全的类,java.util.concurrent 中的 CopyOnWriteArrayList 是一种更好的选择。
LinkedList 与 ArrayList 功能也比较相近,从功能的角度上来说,它们之间最大的区别在于 ArrayList 支持随机访问,而 LinkedList 则不支持。LinkedList 部分代码如下,可以看到 LinkedList 底层使用的是双向链表的数据结构。而且还实现了 Deque 接口,所以除了可以作为列表容器来使用之外,还可以作为队列或者双端队列来使用。
class LinkedList<E> extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
}
LinkedList 同样在 java.util.concurrent 中提供 LinkedBlockingQueue 和 LinkedBlockingDeque 来实现同样的功能,除了在多线程环境比 LinkedList 更有优势外,功能方面基本没有差别。
Set
各类 Set 的共同点在于 set 的元素是不重复的,这一特性在一些情况下非常有用,HashSet 是用的最多的 Set 类。以下是 HashSet 的部分代码,比较有意思的是 HashSet 底层是使用 HashMap 实现的,所有的值都存着在 HashMap 的 Key 中,Value 的位置就放一个固定的对象 PRESENT。
class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
private transient HashMap<E, Object> map;
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
}
HashSet 里面的元素是无序的,如果需要让 set 中元素有序,那么就可以使用 LinkedHashSet,LinkedHashSet 中通过构造一个双向链表来记录插入顺序。而 TreeSet 则是通过底层的红黑树结构提供了排序顺序的访问方式,具体用哪种可以看具体的需求。同样 Set 也有线程安全的版本 CopyOnWriteArraySet。
Queue
Queue/Deque 是 Java 中的提供的 队列接口。ArrayQueue 是具体可以使用的队列类,可以作为普通队列或则双端队列来使用。但是队列在并发情况使用的更多一点,使用 LinkedBlockingQueue 或者 LinkedBlockingDeque 会是更好的选择。有时候除了顺序队列之外,可能还需要通过优先级来调度的队列,PriorityQueue 就是为这个需求而生的,在并发情况下与之对应的就是 PriorityBlockingQueue。
Map

Map 的类图结构相对来说就简单很多。所有的 Map 类都继承了 Map 接口。HashMap 是使用的最多的 Map 类,HashMap 也是无序的,和 Set 类似,LinkedHashMap 和 TreeMap 也从不同的方面保证顺序,LinkedHashMap 通过双向链表来记录插入顺序。TreeMap 则是对其中的元素进行排序,可以按照排序的顺序进行访问。
作为 Map 的典型实现,HashMap 代码结构就复杂的多,HashMap 号称是有着 $O(1)$ 的访问速度(只是近似,在极端情况下可能退化成 $O(N)$)。这么快速的关键在于哈希函数的实现,哈希函数好的实现可以帮助键值对均匀的分布,从而有 $O(1)$ 的访问速度,以下是 HashMap 的哈希函数的实现,而且 HashMap 的扩容和处理哈希碰撞等问题的处理也很复杂。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
与 Collection 中的结构类似,HashTable 也与 HashMap 功能类似,但是 HashTable 是线程安全的。同样因为 HashTable 实现的方式不如 java.util.concurrent 中提供的性能好,所以不推荐使用 HashTable。在并发情况下推荐使用 ConcurrentHashMap,ConcurrentHashMap 通过分段锁的机制,在并发情况下也能有较好的性能。如果在并发情况下也需要保证 Map 的顺序,那就使用 ConcurrentNavigableMap。
Collections 工具类
在 java.util 包下有一个 Collections 类,这是一个工具类,里面所有的方法都是静态的,而且类不能被实例化。里面提供了各种方法,可以用来更有效率的操作各类容器对象。
比如对 List 排序:
ArrayList<Integer> list = new ArrayList();
list.add(1);
list.add(4);
list.add(6);
list.add(2);
list.add(8);
Collections.sort(list);
当然还可以自定义排序的规则,自己实现一个 Comparator 然后作为参数传入就好了。
Collections.sort(list, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1 > o2 ? 1 : 0;
}
});
还有开箱即用的二分查找算法:
Collections.binarySearch(list, 2);
还可以直接把 list 进行反转:
Collections.reverse(list);
还可以把 list 使用洗牌算法打乱:
Collections.shuffle(list);
以上只是其中的一部分方法,还有可以交换 list 中的元素,找出 list 中的最小、最大值等方法。
因为 java.util 包下的容器大部分都不是线程安全的,Collections 有一类方法可以把 普通的容器对象转成线程安全的对象:
Collections.synchronizedList(list);
对于 Map 和 Set 也有类似的工具方法。
在并发环境下,还可以把一个普通容器对象转化成一个不可变的容器对象,这样在并发环境下也是线程安全的:
Collections.unmodifiableList(list);
(完)